{kind=link}
|
|
|
|
The Sanskrit Heritage Engine Reference ManualAbout the Sanskrit Heritage SiteThe Sanskrit Heritage website, at URL sanskrit.inria.fr, provides tools for the computer processing of Sanskrit.This site offers public access to various Web services and Sanskrit lexicons since 2003. It offers dictionary search, declension/conjugation, stemming, and segmentation/tagging/parsing of Sanskrit sentences. The site started as a set of tools to exploit a digital version of the Sanskrit Heritage Dictionary, which had been developped as a personal independent project by Gérard Huet since 1996 as a Sanskrit-French dictionary intended as a small encyclopedia of Indian culture. These tools use the finite-state methods implemented in the Zen Objective Caml library to provide efficient lexicon representation, morphology generation, and segmentation by sandhi recognition. This technology was published in 2005 as A Functional Toolkit for Morphological and Phonological Processing, Application to a Sanskrit Tagger. A graphical interface, designed jointly with Pawan Goyal, has been published recently as Design and analysis of a lean interface for Sanskrit corpus annotation. Written on October 1st 2025, for Sanskrit Engine Version 3.72. First approach to using the Sanskrit Heritage engineThe following scenario may be played remotely, if you are connected to Internet with a Web browser. Visit URL sanskrit.inria.fr to go to the standard Inria Sanskrit Heritage server. Or, if you prefer linking to the Monier-Williams Sanskrit-English dictionary, go to URL sanskrit.inria.fr/index.en.html. The same scenario may be played locally, if your workstation is equipped with its own HTTP server, and if you install the Sanskrit Heritage Engine software. This is explained below in the section How to install the Heritage Engine on your own server.What you are seeing on the entry page is a somewhat ancient-looking Web document in the HTML style of the 90's. Don't be put off by the look-and-feel, but rather thank Inria for supporting this effort without throwing advertisements at you or storing your connection data in cookies.
The page has a green bar at the bottom, which is the navigation control panel.
Just click on the Reader link and you reach the Sanskrit Reader Companion page.
This page gives you access to a Sanskrit analyser, that will attempt to
interpret a Sanskrit input sentence as a list of Sanskrit words,
themselves informed with their morphology.
Our Sanskrit Reader has many parameters, that may be set in this interface page.
First is a toggle "Lexicon access", which is set by default to "Heritage"
if you access the site at URL sanskrit.inria.fr, and at "Monier-Wiliams"
if you access it at sanskrit.inria.fr/index.en.html.
For the sake of the example, let us assume the toggle is set to Heritage.
Next there a toggle Text, set to Sentence, and Format, set to Sandhied.
Now you have choice of the font used by the tool to display Sanskrit text.
It is set by default to phonemic romanization in the "IAST" standard,
but may be set to "Devanagari".
Below the Input line are more toggles. An important one is the Input
convention. It proposes a choice of input text formats. The first four
choices are ASCII phonemic encodings, and are meant for users who want to
type-in the sentence from their keyboard. Velthuis and KH (Kyoto-Harvard)
are two antique and incomplete encodings, WX from University of Hyderabad
and SLP1 from the Sanskrit Library are correct, but hard-reading.
The serious alternatives are IAST and Devanagari in UTF-8 encodings
like you will find on the Web. Let us select IAST.
The next toggle, "Optional topic", should be ignored.
Last is a toggle "Mode" that gives various modes of use of the Reader tool.
In this first experiment, let us set Mode to "All".
Now we are ready. Select as input
"prāptavyam arthaṃ labhate manuṣyo devo'pi taṃ laṅghayituṃ na śaktaḥ",
for instance by copying it from this manual with your mouse,
and pasting it into the input zone. Now press the button "Read".
You now see the result of segmentation of the sentence, in a page
showing a graphical display with colored
rectangles labeled by word forms. Notice how
The display actually represents all possible decompositions of your sentence
into padas (inflected word forms),
aligned on your input represented in the blue line above.
Blue rectangles are subantas (adjectives and substantives), red rectangles
are tiṅantas (finite verbal forms).
Indeclinable words (adverbs and particles) are purple,
pronouns are sky blue, vocative forms are green.
When you click on a rectangle, its morphology is displayed.
For instance, clicking on the red labhate reveals that it is a 3rd person
singular form of the present of root labh in the middle voice
(ātmanepadī) of present class (gaṇa) 1.
Furthermore, underlined labh is a link to the lexicon,
which you may visit to check its meaning, "to obtain".
Furthermore, in the Heritage dictionary,
you get in addition the grammatical information:
[1], indicating that root
labh belongs to class (gaṇa) 1.
This index is itself a link to the conjugation
service. If you click on it, it will display the tables of the conjugated forms
of labh, as well as all its
participial stems. These stems, e.g. past passive participle labdha, are
listed as gendered stems, the gender marks being links to the declension
service. This exhibits the generative nature of the lexicon: all the forms
obtainable from a root, either as finite conjugated forms, or as declined
first-level nominals (kṛdanta), are the building blocks of our analyser.
Similarly, if you click on the blue artham form in the graphical
display, you will get its lemma as singular accusative of masculine stem
artha. This stem itself is a link leading to the corresponding lexicon
entry artha, decorated by active gender marks.
If you click on blue prāptavyam, however,
you see a more complex morphological decomposition, informing you that
it is a form of the kṛdanta (primary nominal stem) prāptavya,
obtained by prefixing the preposition pra- to
the 3rd formation (in -tavya)
of the passive future participle (gerundive) āptavya of root āp.
Please note how the root is linked to its lexical access, from which the
stem āptavya and form āptavyam may be derived using the
conjugation cum declension tools.
Here we are lucky - the correct word analysis (padapāṭha) of the
sentence is obtainable as the sequence of all the words in the upper line
of the diagram. Some have no competitor, they are marked with a blue
check sign.
The remaining ambiguous segments have two marks, a green check sign
and a red cross sign.
In two clicks on the green upper signs you get the intended segmentation.
Now let us return to the Reader window, and remove all the blanks in your input:
"prāptavyamarthaṃlabhatemanuṣyodevo'pitaṃlaṅghayituṃnaśaktaḥ".
The segmenter now returns more solutions, 54 instead of 6, and you see
unexpected new forms appear, such as prāptavyamartham,
whose stem happens to be lexicalized as the name Prāptavyamartha of
the young boy from the Pañcatantra, blamed by his father for having bought
a book containing just one poem, starting precisely with our sentence.
Other forms such as ude or evaḥ
are just noise due to sandhi ambiguity. But the
correct segments appear here too in prominent places, and in 3 clicks the
correct solution is easily attained. Note how clicking on blue segment
manuṣyaḥ determines unambiguously the next one devaḥ.
If you click on a selection by mistake, it is easy to backtrack by clicking
on the Undo button of the page. Other command links on the same
line (Filtered Solutions, UoH Analysis Mode) should be ignored at this stage,
and will be explained in section Shallow parsing below.
Now try again the same example, but now using parameters Monier-Williams
for Lexicon Access in order to get the English gloss of the meanings,
Devanagari both for Sanskrit Display Font and Input convention, and input:
"प्राप्तव्यम् अर्थं लभते मनुष्यो देवोऽपि तं लङ्घयितुं न शक्तः".
The Declension tool accepts 4 gender parameters:
Mas for masculine, Neu for Neuter, Fem for Feminine,
and a final All that is to be used for deictic personal pronouns,
and for numbers.
The Conjugation tool accepts 11 Present class parameters: 1 to 10 are used
for the traditional quality (gaṇa). 11 is used for denominative verbs.
Secondary conjugations: causative, intensive, and desiderative are listed
as well.
Please note that in the Roman output the first person appears first,
whereas in the devanāgarī output the third person appears first
(prathama), consistently with vyākaraṇa tradition.
Parameter 0 may be used for displaying conjugations of a root not admitting
the present system, such as "ah".
Homonyms are adressed using homonymy indexes, like in kara#1 and
kara#2. In case of doubt, access the tool from the intended entry in
the lexicon.
If you do not specify the index, the system will make an educated guess of
the intended homonym. For instance, if you ask for the conjugation of
root mā in class 1, the system will propose the forms of mā_4, and
in class 2 or 3 it will propose mā_1. But if you intend mā_3
of class 3 you must address it explicitly as maa#3.
If you enter random stems and parameters, you will get arbitrary nonsense,
according to the principle "garbage-in garbage-out". Thus if you ask for the
declension of stem blablabla in the masculine you will get
nonsensical forms such as ablative blablablāt.
But at least you are warned by the
system, that indicates its doubt by labeling the declension table as
?blablabla. And if you ask for its forms in the feminine,
you will get a Gender anomaly report.
This morphological engine is available from within the dictionary pages,
where the gender indications of nouns, and the present family indications
of roots, are active links which activate the Sanskrit Grammarian with the
correct parameters. However, in the Monier-Williams dictionary, only
declension links are available, but not conjugation links of roots.
The user must provide the lexical category where to search the word from.
Available categories are Noun, for nominal and adjectival forms,
Pron for pronominal forms, Verb for finite root forms, Part for participial
forms as primary derivatives from roots, Inde for indeclinable forms (adverbs,
particles, infinitive forms, root absolutives), Absya for absolutive forms
in -ya (usable with preverbs prefixing), Abstvaa for absolutive forms
of roots in -tvā, Voca for vocative forms,
Iic for stems usable as left component of a compound, Ifc for right
components of compounds, Iiv for inchoative forms in -ī
usable to form compound verbal forms with auxiliaries
(the cvi construction), Piic for participial stems.
Infinitives forms are available in both Absya and Abstvaa.
For instance, forms usable only in fine compositi such as kāraḥ
are to be found in the Ifc bank.
There is some redundancy between the Noun and the Part banks.
Thus a word form such as gataḥ may be found in Noun,
tagged as { nom. sg. m. }[gata], as well as in Part,
tagged as { nom. sg. m. }[gata { pp. }[gam]]. Such lemmatisations are
linked to the lexicon by stems (here gata) as well as by roots
(here gam).
These linguistic resources are freely provided
in XML form under various transliteration schemes.
Please visit the Sanskrit linguistic resources page.
The Sanskrit Heritage Dictionary is the latest edition of a Sanskrit
to French Dictionary
"Dictionnaire Français de l'Héritage Sanskrit" compiled by
Gérard Huet since 1994. This dictionary is freely available
as a 1139 pages book under the pdf format,
easily readable with Acrobat Reader, a free Adobe product.
This dictionary is still under development, and is
automatically updated along with the site,
being now a computer-generated by-product of the lexical database
of the platform.
This dictionary is the basis for morphology generation used by the grammatical
tools. It may be used also as a small encyclopedia of Indian culture.
The Sanskrit name that renders best our encyclopedic intention is
saṃskṛtibhāratīyakośa -
Treasure of India according to refined tradition.
Knowledge in this tradition is traditionally transmitted by lineages of teachers
(paraṃparā). Some of this knowledge is available to the West through
Indological litterature, but often in dessicated form. Many sources were used
to compile this information, and inevitable mistakes and inconsistencies
occur, not to speak of glaring omissions. We pray the reader who knows
better to signal such overcomings to us.
Refined means Sanskrit or Sanskritized.
Thus usual names in vernacular [prakṛta] or pāli are generally
given in their original Sanskrit form. Dravidian names are sometimes adapted
to Sanskrit as an approximate phonetic rendition, but our lexicon is too limited
to account for Dravidian traditions, not to speak of tribal ones.
In any case, this modest dictionary ought not to be considered as a
scholarly erudite document, but rather as a simplified presentation
of Indian culture for the educated public.
Entries in the dictionary are arranged by vocables, which may be verbs or nouns.
Verbs comprise verbal roots, but also their variations with prefix sequences of
preverb particles, and secondary stems for causatives, intensives and
desideratives.
Nouns comprise noun roots, primary noun derivatives from verbs, secondary noun
derivatives by suffixes from primary ones, and compounds.
The first two categories are individual entries
at toplevel, the others are sub-entries of a parent vocable, or sub-sub-entries.
Adjectives are just semantic roles of nominals. Pronouns and numbers are
subclasses of nouns. Indeclinable forms (adverbs) and tool particles such as
conjunctions complete the lexical categories.
Some idiomatic expressions and a few selected
citations are listed at the end of entries at any level.
The list of abbreviations, of the Heritage dictionary as well as the grammatical
engine, is available
as a standalone pdf document.
Two index engines are provided.
The main index
requires exactly transliterated input, possibly an initial
prefix of an existing entry, possibly some inflected form of a declined noun
or a conjugated verb.
The Sanskrit made easy
index requires a romanized input for a full word, without diacritics and
aspiration marks, for easy access to words like Siva, Vishnou, Panini,
Sankara, etc.
The user who opts for
Monier-Williams access
will have the benefit of seeing
definitions in English if he does not know French, while having access to
the grammatical online tools in the same way. However proper names are not
properly glossed as hyper-linked entities. Furthermore, the index tool
is not as smart as the Heritage one, since you have to give the exact
stem of the entry. Thus e.g. devanāgarī must be entered in full,
while the initial prefix devanāg suffices for its disambiguation
by the Heritage index.
The Sanskrit Heritage dictionary is also available in an older version
under ebook format,
usable with the Babyloo, Stardict or Goldendict software.
Please visit the Golden Sanskrit Heritage page.
The parameter "Lexicon Access" chooses the look-up dictionary. This parameter
is persistent within a session. On the standard server it is set by default
to Sanskrit Heritage, but if you are an English speaker you may want to set it
to Monier-Williams, by accessing the
English entry URL.
If you install the tools on your own server, you will set such default
parameters at configuration time.
You should be aware that the choice of the look-up dictionary is of no
consequence to the reader tools, since the morphology generation lexicon
is Sanskrit Heritage. Thus the forms of certain stems in Monier-Williams
may not be recognized (however, see
user-aid below for their acquisition).
Conversely, the richer generation of participles allows the recognition
of many forms, whose stems are not lexicalized in Monier-Williams.
The covering of Heritage within Monier-Williams is indicated explicitly
since entries lexicalized in Heritage are rendered highlighted in yellow in
the Monier-Williams pages.
The parameter "Cache" is for advance use, explained below in
user-aid.
The parameter "Text" is set by default to Sentence, and may be set to Word
if you want to recognize a single pada.
For instance, if you parse the following compound (taken from Pañcatantra):
"pravaranṛpamukuṭamaṇimarīcimañjarīcayacarcitacaraṇayugalaḥ"
in Sentence format, you will be offered 96 solutions, but only 6 solutions
in Word format, and a unique one in First mode. Furthermore, explicit hyphens
in the input help the disambiguation, like:
"pravara-nṛpa-mukuṭa-maṇi-marīci-mañjarī-caya-carcita-caraṇa-yugalaḥ".
The next parameter "Format" is a toggle between reading sandhied text and reading
text which has already been analysed in words (padapāṭha).
Thus the sentence "siṃhovyākaraṇasyakarturaharatprāṇānmuneḥpāṇineḥ"
my be parsed in Sandhied format (yelding a total of 26 potential solutions),
or may be presented in Unsandhied format as
"siṃhaḥ vyākaraṇasya kartuḥ aharat prāṇāt muneḥ pāṇineḥ"
(yielding only 18 solutions in All mode, and only one in First mode).
The parameter "Sanskrit display font" may be set to Devanagari or to IAST,
according to the desired rendering for Sanskrit text.
The "Input convention" parameter allows a number of formats. Transliteration
using ASCII characters is possible in 4 varieties: Velthuis, WX (University of
Hyderabad), KH (Kyoto-Harvard), and SLP1 (Sanskrit Library). These various
conventions are presented in a
synthetic document.
Thus vaiśeṣikaḥ may be input as vaize.sika.h in the default Velthuis scheme,
as vaizeSikaH in the Kyoto-Harvard scheme, as vESeRikaH in the WX
scheme, or as vESezikaH in the SLP1 scheme.
In addition, Unicode input
may be used, both for devanāgarī and for the IAST romanisation with diacritics,
the Indology standard. Thus one may input directly वैशेषिकः or vaiśeṣikaḥ.
The "Optional topic" parameter is used in Parser mode to indicate a contextual
topic usable as ellipsed agent. This is an experimental feature.
Finally, the "Mode" parameter offers several modes of operation of the Engine.
Three modes are available under the graphical display format: First, Best
and All. The most complete one is All, that gives all available segmentations,
and that generally over-generates. Whereas mode First, currently the default
one, gives only the most
probable solutions, according to a statistical analysis. The mode Best is
intermediate between the two.
We saw the default Summary mode. Other modes, such as "Tagging" are provided
to display all solutions sequentially (with explicit sandhi information).
These modes are mostly deprecated, since they
produce enormous pages when there are many solutions. It is possible to access
these modes from the graphical Summary mode, when there remain only a
few solutions.
Finally, the Analysis mode may be used to continue the shallow analysis
of the tool into a deeper semantic analysis provided by the
University of Hyderabad Saṃsādhanī dependency parser. This facility
is also available form the other modes, under the choice of "First Solution".
This facility is still experimental, and will not be fully documented in this
version of the manual.
In this example, the machine has succeeded in focusing on a correct solution
automatically, among many interpretations.
If we come back to the initial selection, it indeed tells
"1 solution kept among 22",
but actually lists also 4 other plausible additional solutions. Indeed, among
them, Solution 19 gives another correct decomposition śvā+itaḥ+dhāvati
"The dog is running towards here". Here too, the tool analyses dhāv_1
as fitting the grammatical constraints. It has penalty 0 as well, but
was just disfavored over the first interpretation because it has 3 segments
rather than 2, exhibiting a "shortest number of words bias" heuristic.
This shallow parser cannot be used on large input sentences, since its output
could become enormous to the point of choking the server. Thus we have its
access link "Filtered Solutions" appear only when the number of remaining
segmentation candidates is below a threshold set by default to 100.
This is in contrast with the situation with the graphical interface, which
is fast and robust. Thus entering the following verse from Kālidāsa, we obtain
very quicky a display factorizing an astronomical number
(3383038148345856) of solutions:
yā tapoviśeṣapariśaṅkitasya sukumārampraharaṇam mahendrasyapratyādeśaḥ rūpagarvitāyāḥ śriyaḥ alaṅkāraḥ svargasyasānaḥ priyasakhyurvaśī kuberabhavanāt pratinivartamānāsamāpattidṛṣṭena keśinādānavenacitralekhādvitīyā bandigrāhaṅgṛhītā.
-->
Actually, complex compounds with n+1 components appear as a sequence of n
yellow segments denoting stems, followed by a blue nominal inflected form.
For instance, enter in the Reader the following input (IAST)
pravaranṛpamukuṭamaṇimarīcimañjarīcayacarcitacaraṇayugalaḥ
or प्रवरनृपमुकुटमणिमरीचिमञ्जरीचयचर्चितचरणयुगलः (Devanagari). Using First mode, we get
a unique segmentation displayed, of one compound pada with many yellow
stem segments.
Actually, there are remaining
ambiguities concerning the bracketing of these constituents. Let us examine
a few typical situations.
First of all, some contiguous constituents may constitute a dvandva
compound. For instance, consider yakṣagandharvanāgāḥ.
It is a dvandva compound with 3 components yakṣa,
gandharva, and nāgāḥ. The first two are bare stems, only
the third one bears declension (vibhakti). Note that actually we
distinguish two cases of the last segment: a blue one for nominative,
and a green one for vocative. This distinction between vocatives
and other cases is important, since vocatives are not really syntactic
components of a sentence, but rather separate interjections, part of the
communicative structure. We also note on this example, analysed in All mode,
the parasitic nā- a rare nominative form for man (nṛ), which is
ignored in mode First because of its low frequency.
Let us now consider binary branching compounds. A three component display
A-B-C may actually represent the compounding structure (A-B)-C
(for instance viśvarūpadarśanam) or (less commmonly) the structure A-(B-C)
(for instance ubhayacakravartī). Thus long compounds are represented
in ambiguous ways, since the mechanical reader does not know how to choose
between them on the sole basis of grammatical dependencies.
Now consider the compound pītāmbaram. It may denote a determinative
compound (tatpuruṣa), meaning "yellow garment", of neuter gender
inherited from its component ambara. Or it may denote an exocentric
compound (bahuvrīhi), of adjectival meaning "who wears a yellow garment".
Thus, on input pītāmbaram, in modes (Word, All), we have two solutions,
sharing the yellow initial component pīta. The first solution proposes
a blue neuter nominal segment ambaram, analysed as accusative or
nominative of stem ambara in the neuter gender.
The second ambaram however is of a distinct cyan colour,
and is analysed as masculine accusative. This second solution is mandatorily
the exocentric compound "he who wears a yellow garment", typically an
epithet of Lord Viṣṇu. The cyan colour segment may not occur stand-alone,
it is obligatory preceded by a yellow segment in order to form an
exocentric adjectival compound. But the first solution is ambiguous,
since it may be interpreted as a tatpuruṣa or as a bahuvrīhi.
This example ought to be thoroughly understood in order to learn how to
select the segments corresponding to the intended meaning.
There exists yet another variety of compound, the so-called avyayībhāva
"turned into indeclinable". Let us consider a typical example,
nirmakṣikam (without flies). Here, again in modes (Word, All),
this input is analysed as a sequence
of segments, first the preposition nis, colored lavender, and then the
stem makṣikā, turned into an invariable form makṣikam,
colored magenta. Please note that the segment makṣikam is not accepted
as stand-alone input. Also note on this last example that an
unrecognized chunk of input yields a grey rectangle with undefined morphology.
Verbal compounds exist, such as the periphrastic perfect construction,
used for secondary conjugations and nominative verbs. It builds
a special stem in -ām, suffixed by a perfect form of
one of the auxiliaries kṛ, as and bhū.
Try for instance āmantrayāṃcakre. You see the periphrastic form
displayed as two segments, an orange āmantrayām, and the red
cakre of the perfect of root kṛ: "he/I summoned". The orange
and red segments are mutually linked, thus selecting one selects automatically
the other.
Another periphrastic construction is the inchoative "cvi" verbal compound.
Its left part is a special substantival stem in ī or ū,
and its right part a finite verb form of one of the auxiliaries,
like kadarthīkaroti (he despises) or mṛdūbhavati (it softens).
It may also give rise to primary derivatives (kṛdanta) like
khilībhūtaḥ (abandoned). Here too the left part is orange,
and the right part is either red for verbal forms, blue for participial forms,
like kadarthīkṛtaḥ, or mauve for absolutives and infinitives, like
respectively nimittīkṛtya and nimittīkartum.
This construction also avails for a number of word forms
usable before auxiliary verbal forms, and traditionally called gatis,
such as sākṣāt, mithyā, namas, etc.
This concludes the main grammatical paradigms implemented by our machinery.
Some more exotic constructions may occasionally be met, like
the special construction of forms of kāma or manas,
preceded by a special infinitive verbal form in -tu. Try for instance
vaktukāmaḥ ("who wants to speak"). Note that two blue segments
kāmaḥ appear in the result. One is used as a stand-alone nominal form
(if you select the red imperative form vaktu), whereas the other one
is necessarily used together with the salmon-colored special infinitive segment
vaktu. Similarly for draṣṭumanāḥ ("inclined to see").
Another interesting example is virodhitayā. The two blue segments look
alike, and they are both instrumental singular forms of the feminine stem
virodhitā. But one is the past participle of the causative of
verb vi-rudh, the other is an abstract taddhitānta noun,
obtained as virodhi(n)-tā. Distinguishing the two is essential, since
they don't have the same dependency, the first one being an adjective
requiring a substantive as its qualificand.
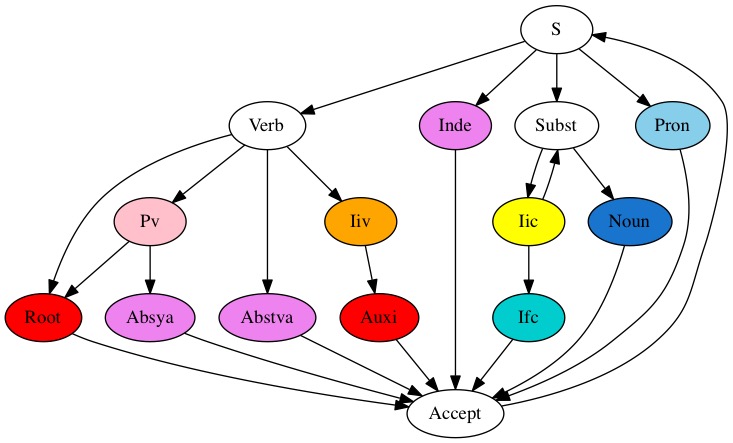
In order to understand the segmenting algorithm, one should study its control
automaton. Here is a simplified automaton,
explaining the main constructions.
Words (pada) are recognized by paths going doing from the starting state
S, and ending in the accepting state Accept. The link going upward from Accept
to S allows to recognize a sentence as a sequence of words, sandhi being
effected on the arcs of the diagram. Please note the cycle through state Iic,
allowing the recognition of arbitrary length (flattened) compounds.
The results returned by our graphical interface may be thought of as describing
all paths following such a state diagram, except that preverbs are glued
to the root and participial forms following them. The actual automaton
has many more states, accounting for more constructions.
Once you access Saṃsādhanī, you have all the functionalities of this tool
available, up to the production of dependency graphs labeled with semantic
relations, and ranked by decreasing satisfaction of dependency constraints.
We shall not explain further this facility, for which we refer to
Saṃsādhanī's own documentation.
Note that in the system's rendering, the mandatory space is indicated by
an underscore symbol. Indeed, the user may use underscore to mark the
necessary pauses, and thus the above example may be entered without any
space as vanādgrāmamadyopetyaudana_aazvapatenāpāci.
On the other hand, a blank may be inserted between letters even though
the separate chunks are not in final sandhi, like after vanād above,
or in vanaṃ gacchati. Thus Sandhied format with optional blanks
is completely different from Unsandhied format, where each chunk of input must
be a pada in final sandhi form, like in:
vanāt grāmam adya upetya odanaḥ aazvapatena apāci.
When entering digitalized corpus in our machinery, one must understand well
this distinction, and possibly restore a consistent input.
The nasalisation sign anusvāra is optional when it stands for a nasal, and
mandatory only before sibilants and h. Thus sandhi and
saṃdhi are equivalent. Similarly for visarga before a sibilant. Thus
śunaḥśepa or śunaśśepa.
Sandhi of n before l (anunāsika) is noted in our adaptation of
Velthuis notation by a pair of tilde symbols, like in vidvaal~~likhati,
leading to candrabindu in devanāgarī, like: विद्वालँलिखति.
It is also possible to help the segmentation of compounds, by inserting a
hyphen at the stem boundaries. For instance, the long compound:
"pravaran.rpamuku.tama.nimariicima~njariicayacarcitacara.nayugala.h"
may be disambiguated to a certain extent as:
pravara-n.rpa-muku.ta-ma.ni-mariici-ma~njarii-caya-carcita-cara.na-yugala.h
When initial short a is deleted by sandhi, it is possible to
indicate the situation with the avagraha
sign, noted by an apostrophe ' in
transliteration. Actually this notation is mandatory in certain situations
(after e and o) like devo'pi. Thus the Bhagavadgītā verse
नासतोविद्यतेभावोनाभावोविद्यतेसतः will only accommodate Śaṅkara's analysis
na asataḥ vidyate bhāvaḥ na abhāvaḥ vidyate sataḥ, whereas
Madhva's interpretation (with abhāvaḥ) has to be made explicit as
नासतोविद्यतेऽभावोनाभावोविद्यतेसतः
Finally, the system does not currently support degemination of stems,
such as modern renditions of tattva as tatva
or vārttā as vārtā; only a few common stems such as
chatra, chātra and patra are recognized.
A special warning must be given concerning vocatives. Because vocative forms
of the common substantives ending in a are undistinguishable
from their bare stem, usable in compound formation, we demand that vocatives
are chunk-final, i.e. ended by a space in the input. Thus
rāma aśvampaśya may not be written rāmāśvampaśya: in this second
input, vocative form rāma is not recognized. This poses a problem
only in the cases where the extra space would be interpreted as non-trivial
sandhi, like for instance in rāma odanampacatu, or in
śatakrato vivardhasva. In such cases, ending the vocative
with an exclamation mark ! will allow the proper vocative recognition,
like rāma!odanampacatu and śatakrato!vivardhasva. More
generally, this exclamation mark may be used for explicit padapāṭha.
dṛṣṭvā tu pāṇḍavānīkaṃ vyūḍhaṃ duryodhanastadā |
Please note that this notation is mandatory for such examples, where the
first verse should not be glued by sandhi to the second one.
This is a set of tools to browse and manage a corpus. You can explore
the corpus tree and possibly add and modify the analysis of
a sentence. There are three modes of use (if you install the platform
in the Station mode) :
When you place yourself in a certain corpus location (foo/bar for
example) and you decide to add a new sentence, you are directed to the
Sanskrit Reader Companion (note the subtitle "Corpus annotator mode -
foo/bar") to enter a new sentence to be added to the corpus at the
location you clicked on the "Add" button.
Every time you want to switch from a mode to another you have to click
on the "Corpus" link in the green control bar at the bottom. If you
simply want to go back quickly to the top of the corpus hierarchy
preserving the current mode, you can click on the title of any page of
the corpus browser.
The complete Ocaml source of all modules of the Heritage Engine is available
in literate programming style as a pdf document
Heritage_platform_documentation.
It may be considered as our vyākaraṇasūtrasaṃgraha.
In order to install it, you must download three git repositories:
Your first installation may be tricky if you are not familiar with the
UNIX/Apache technology.
But once your config file is correct, it will be very easy to install
updates, as summarized in the document INSTALLATION in the top distribution
directory of the Platform.
Signal installation difficulties and relate your experiences with these tools
to Gerard.Huet@inria.fr.
A useful supplement to this manual is our page of frequently asked questions
Faq, also available from the "Help"
button on the site control bar.
|