Frequently asked questions about the Sanskrit engine

How to interact with the Reader
Click on ✓ to select segment, click on ✓ to rule out segment.
Click on colored rectangle to get its morphology information.
Why is the green menu bar inconveniently placed?
The green menu bar is supposed to stick at the bottom of the page. If it appears in the middle of the page, sometimes hiding essential dialog boxes and buttons, it is that your browser is not XHTML compliant. Normally the sliding bar allows all the text to be pulled and made visible. If you encounter difficulties with either Safari, Chrome or Firefox, please report the precise problem with the precise versions of browser and OS used.
Is the interface compliant with the Unicode standard?
Yes. The Sanskrit printed by the system is encoded as strings of Unicode, in two flavors - romanisations, rendered as roman script with diacritic marks, such as vaiśeṣikaḥ, and devanāgarī representations, rendered with proper ligatures if your browser has appropriate fonts loaded, such as वैशेषिकः
The input windows may accept Unicode input under UFT-8 encoding, either in devanāgarī, or in Indological romanization script. It accepts alos transliterated encoding, where diacritics are special characters such as quotation signs and periods, long vowels are noted by duplication, and the whole phoneme stream should be represented as an ASCII string, such as vaize.sika.h.
What is the default transliteration convention?
The default roman transliteration scheme stems from Velthuis' devnag TeX input conventions. The left table gives you the transliteration convention for each Sanskrit letter, the right table shows its rendering with usual diacritic conventions:
|
|
|---|
Alternatively, you may write "s instead of z and "n instead of f. Note that upper case letters are reserved for initial capitals in proper nouns. Thus A is NOT equivalent to aa (however read the next section for alternative schemes). Such proper nouns are accepted only in the "Sanskrit made easy" search engine. See proper names below.
Other known transliteration schemes
The Sanskrit platform allows the optional use of three other transliteration schemes, the so-called Kyoto-Harvard scheme KH usual for Western indologists, the WX scheme used at University of Hyderabad and other Indian sites, and the SLP1 scheme of the Sanskrit Library. Thus for instance the word tacchrutvā may be input as tacchrutvaa in the default Velthuis scheme, as tacchrutvA in the Kyoto-Harvard scheme, as wacCruwvA in the WX scheme, or as tacCrutvA in the SLP1 scheme. Similarly vaiśeṣikaḥ may be input as vaize.sika.h in the default Velthuis scheme, as vaizeSikaH in the Kyoto-Harvard scheme, as vESeRikaH in the WX scheme, or as vESezikaH in the SLP1 scheme. A convenient table compares the various encodings. In order to choose a transliteration scheme other than the default, click on the corresponding radio button in the interface pages.
devanāgarī input
It is now possible to enter Unicode representation of devanāgarī in UTF8 encoding. Just press the Deva button associated with the input window. Try for instance searching for: देवनागरी or for devanāgarī.
How come the devanāgarī rendering I see is wrong?
This question is complex. It depends on your browser and its proper parameterization, on the rendering engine of the operating system and its windowing library run on your station, and on the fonts which are actually available in ts library. In particular, it is the rendering engine that compiles the ligatures into actual glyphs displayed on your screen. Thus this site may be seen more or less correctly according to your local configuration. Do not blame me if you get garbage on Explorer or Netscape. I personally use Safari on MacOSX, and the rendering is generally good. I occasionally check on Firefox and Chrome for interoperability, and I try to insure that my Web pages are compliant with the W3C specification for HTML5. I give some indications about proper fonts to load on the entry page of the site.
How should I present stems to the grammarian?
The grammatical engine has two interfaces, one for the declension of nouns, adjectives, pronouns and numbers, the other for the conjugation of verbs. When it is activated from links in the dictionary, the results are displayed in Roman script with diacritics. When it is activated directly (from the Grammar link in the green menu at the bottom of the page), it gives you as option to display in devanāgarī. Note that for declensions the first person is listed first in Roman, consistently with Western tradition, whereas in devanāgarī the prathama puruṣa is listed first, consistently with Indian tradition.
The parameters of the declension engine are the stem and the gender. The stem must be presented in the same style as in the dictionary. For instance, a present participle should be presented with its weak stem (e.g. tudat), and not with its strong stem (tudant). When the stem does not correspond to a dictionary entry, the declension table is given with the input stem marked with a question mark, indicating that this word is not known from the lexicon, and thus the displayed forms may not be trusted. For some combinations of stems and genders an error message may be displayed. When the entry does exist, the answer provides its link to the dictionary. In this case, however, the forms returned are not obtained by table lookup, but are recomputed on the fly.
The gender parameter may be Mas for masculine, Fem for feminin, Neu for neuter, or the special parameter Any which is reserved for deictic pronouns (such as aham, tvad, ātman) and numbers (eka, dva, ...) but also kati.
The parameters of the conjugation engine are the stem and the present class. Here as in the declension engine, an attempt is made to guess a possible homonymy index from the parameters. Thus if you enter stem vid and press on the button marked 2, you will get the forms of root vid_1 (such as vetti), whereas if you press on the button marked 6 you will get the forms of root vid_2 (such as vindati). If you want the forms of vid_1 of class 6 (such as vidati) you have to enter explicitly vid#1.
The forms displayed are the forms of the present system in the indicated class, followed by all forms of other systems known to the machine, in the primary conjugation as well as in the derived conjugations. Not all seven forms of aorist are given for every root, only the ones that correspond to a paradigm explicitly listed (from 1 to 7) in the lexicon. In the present version, the only passive forms are those of the present system (plus the passive aorist 3rd person forms such as agāmi, listed in the middle/reflexive voice table).
The participles section lists a collection of participial stems in the 3 genders. Their gender marks are mouse sensitive links, which call the nominal declension tool to display the corresponding adjectival stems. Thus a strongly generative root such as nī may lead literally to thousands of forms.
Not all returned forms are attested, we have been rather generous in permitting both active and middle/reflexive voices for many roots.
All the forms obtainable from the dictionary entries are listed in morphological bases, available both in XML and in pdf formats. We remark that in these tables the conversion of final r or s to visarga has not been effected. This is essential for the correct analysis by the segmenter of constituants such as punarapi, obtainable by external sandhi from forms punar and api. Thus the visarga-ended forms displayed by the grammatical engines, consistently with the Indian tradition, actually correspond to an information loss at the time of display.
How should I present sentences to the reader/parser?
Sanskrit input is presented to the parser in two possible forms.
The first form is the saṃhitāpāṭha continuous representation. All words are
linked together via sandhi. A hiatus between vowels is noted by _ (underscore), and
elision of an initial a is noted by ' (apostrophe) for avagraha.
It is also possible to represent the input in padapāṭha separated form, where
individual words, represented in terminal sandhi, are separated by spaces.
The Sanskrit Reader gives you a choice between the two input conventions by the control button Sandhied (saṃhitāpāṭha) or Unsandhied (padapāṭha). The default is Sandhied. In this mode, spaces are allowed too to help the segmenter by indicating word limit places. Then, the successive chunks of input are not assumed to be in terminal sandhi form. Typically, a terminal o will be reverted as an aḥ if the first letter of the right chunk would turn it into o by sandhi. Similarly an anusvāra ṃ may occur instead of an m.
In both modes, spaces may appear only at the frontier of full words - i.e., you cannot break a compound with spaces, and you cannot put a space between a preverb and a verb form.
Example of input (in VH transliteration):
dvitiiyakak.syaayaa.mdvebaaliketrayobaalakaazcapa.thanti
The same with a few spaces:
dvitiiyakak.syaayaa.m dvebaaliketrayo baalakaaz ca pa.thanti (in Sandhied mode) or
dvitiiyakak.syaayaam dvebaaliketraya.h baalakaa.h ca pa.thanti (in Unsandhied mode).
Note that we now have significantly less solutions (6 instead of 13).
Fortunately, the parser is smart enough to propose only one solution
in both cases.
A phrase obtained by sandhi of atas and atas may be represented as ato'ta.h in both modes, as ato 'ta.h or ato ata.h in Sandhied mode, but only as ata.h ata.h in Unsandhied mode.
Adding spaces may help the parser by giving segmentation hints. Also it helps focusing on the difficulty when a chunk is not analysable. The difficulty may be yours, such as a spelling or transliteration mistake. It may also be due to the limited coverage of our lexicon.
In rare cases, it is not possible to split the input after the final o of forms such as vocatives of nouns in u.
Most hiatus situations may now be handled in Sandhied form with a space
rather than an explicit underscore.
For instance consider
ti.s.thanbaalaka upaadhyaayasyapraznaanaamuttaraa.nikathayati,
equivalent to ti.s.thanbaalaka_upaadhyaayasyapraznaanaamuttaraa.nikathayati.
Here the padapāṭha input would be
ti.s.thanbaalaka.h upaadhyaayasyapraznaanaamuttaraa.nikathayati,
and actually this last input will lead to less potential solutions considered, since the form
ti.s.thanbaalake will not be considered as a possible potential segment.
Similarly anya upavi.s.taa.h will correctly interpret the first
component as anye.
The only situation where an explicit underscore is still required is
in VH transliteration, for words such as
tita_u and pra_uga.
The fully unsandhied padapāṭha form, where each chunk is a pada (inflected form of a word) may be recognized by specifying the Text category as Word rather than Sentence, using the corresponding radio button. In this mode, every chunk must be a single word. The best way to tag a single word is to input its form in Word Text category (either in Sandhied or Unsandhied mode, since the two differ only when there are several chunks). Thus, if you input pravaran.rpamuku.tama.nimariicima~njariicayacarcitacara.nayugala.h you get its unique decomposition as a 10 components compound, whereas you would get 16 possible segmentations in Sentence mode.
What is the meaning of the Strength argument to the parser/reader?
Our reader comes in two versions. The Complete version uses all possible participial forms of all roots and will recognize the so called nan compounds (nouns or adjectives using the privative prefix a/an). The Simplified version recognizes such forms only when they are explicitly lexicalized in the Sanskrit Heritage dictionary. Furthermore, only the Complete version allows vocatives. The default version is Complete. The Simplified version may be used for teaching beginners on simple sentences without vocatives, since it is much more precise when it works than the Complete one, which may badly overgenerate. Once the basic competence on using the interactive interface is acquired, the user should switch to the Complete mode.
The precise grammar used to recognize sentences in the Simplified version may be visualized as a local automaton graph: Simple. Compare with the Complete one.
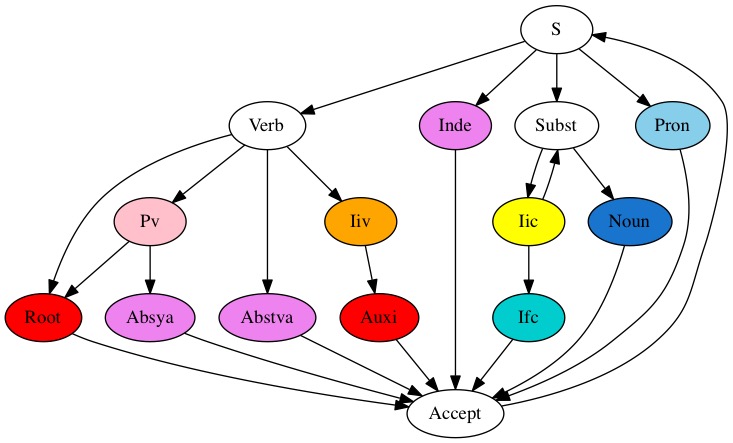{kind=link}
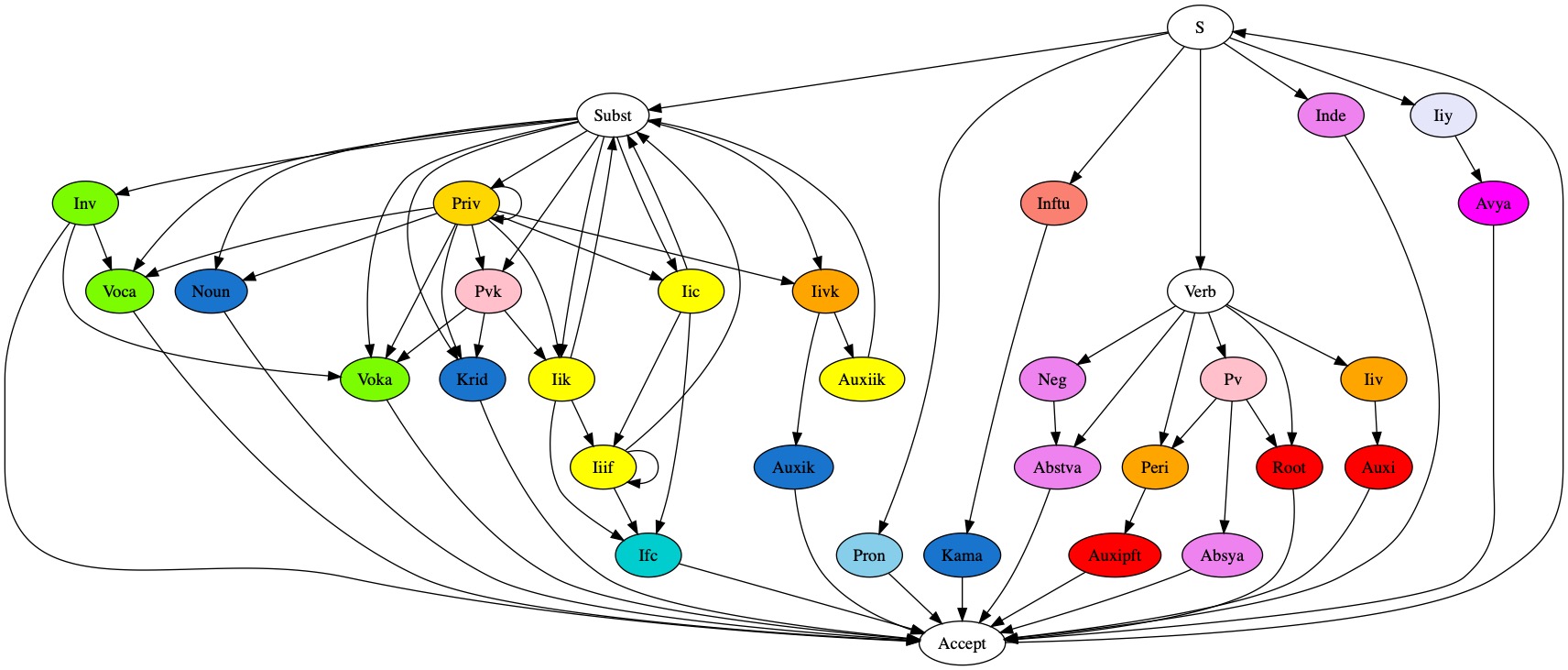{kind=link}
Why does the system not recognize certain participial forms known to the stemmer?
Our Simplified reader/parser does not use all the participles generated by the grammatical engine, and recognized as such by the stemmer, but only the ones that are explicitly listed in the lexicon. If you want the full generative power, use the Complete mode.
What is the use of the contextual topic argument?
It is now possible to specify a contextual topic argument as an ellipsed nominative. This indication is given to the parser by a radio button, allowing choice
between a topic of a given gender and no topic (default value).
By specifying a masculine topic (here corresponding to Rāma),
one may parse successfully sentences with an ellipsed topic. For instance,
the phrase "jayati" parses as a finite verbal form, rather than the locative
of the present participle "jayat".
This feature is still experimental.
Can I cut in the system's output and paste in the system's input windows?
You can now input देवनागरी script in Unicode representation (UTF8 encoding), provided you press the Deva button in the corresponding input window. It is also possible to input romanisation script with diacritics, such as devanāgarī, by pressing the Roma button.
Is the Sanskrit engine available as standalone software?
Yes, please visit the Reference manual.
Where is the list of abbreviations defined?
The list of abbreviations, of the Heritage dictionary as well as the grammatical engine, is given at the end of the introduction of its book form. For the convenience of the Web site users, the list of abbreviations is available here as a standalone pdf document.
What is the policy regarding the rendering of proper names?
Proper names are indicated in the dictionary with an initial capital letter. Proper names are currently allowed for input in the "Sanskrit made easy" interface only. When the initial is a long vowel, it should be doubled, like AAtreya for Ātreya.
Proper names are in general presented in the nominative case, except that a possible visarga is dropped. Thus we write Agni and not Agniḥ, and similarly Śiva, Viṣṇu and Lakṣmī; also Tvaṣṭā, Mātā, Brahmā (the Creator God, distinct from the impersonal all-pervasive brahman principle). Also Atharvā, Mātariśvā, Nandī, Aṅgirā, Viśvakarmā, Kṛtavarmā, etc. But also Aṃśumān, Aryamān, Ketumān, Garutmān and Hanumān. Similarly Iravān, Kakṣīvān, Jāmbavān, Vivasvān, Śaradvān, Satyavān and Himavān.
What is the meaning of Piic?
Piic is a lexical class, it is to participles (Part) what Iic is to nouns (Noun); that is, it stores the raw stems of participles, usable as first component of a nominal compound. Participles are a special case of first level nominal derivatives from roots, called kṛdantāḥ in the traditional terminology.
What is the meaning of Ifc?
Ifc is a lexical class of nominal affixes that may only occur as second component of a nominal compound. More generally, the phases of the lexical analyser are explained as states of a finite automaton describing the Sanskrit morphology. Look at its (simplified) state transition graph here.
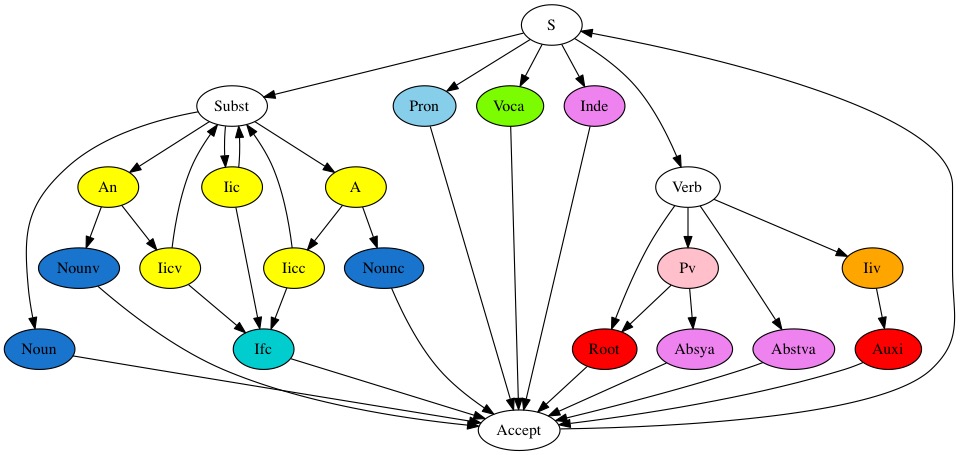{kind=link}
Who is using this site?
This site is used first of all by the researchers of the joint research team in Sanskrit Computational Linguistics, at the Department of Sanskrit Studies, University of Hyderabad, at the Department of Computer Science and Engineering, Indian Institute of Technology, Kharagpur, and at the Sanskrit Library. Many other users are attested worldwide. Some of them are kind enough to send us their appreciations, please visit our Golden book.